Overview of commercial and free thesauri
A simple search for GPS apps for your smartphone these days can turn up results covering everything from baseball players to Moroccan cuisine. Often, Internet search results only make sense when you add terms to the search itself.
The reason lies in the analysis of the language, which is integrated into the search engine's utilization process. This analysis looks at the relationships between the words based on various criteria, which are then used to refine the results. Computers also appear to understand what you are looking for by providing you with exact and varied results even if typos are present within your search terms.
Although the user interface (e.g., an input screen) often appears quite mundane, the process behind these searches has little in common with a simple phrase or keyword search [1]. In the past, a query didn't find files or documents unless the correctly chosen (and correctly spelled) search terms were used.
However, search engines have evolved during the past 20 years into sophisticated language processors in which many criteria play a vital role. Search engines use more than 50 different processes including the language of the document, the format and structure, technical terms within the metadata that register how often a document is referenced, or a link itself (e.g., degree of network integration).
The result then is based on concepts that belong together thematically. In addition to a large dose of statistics, knowledge about the linguistic context of the individual words plays a major role. This originates from the linguistic components of the thesauri (see the "Origins" box).
Origins
The term thesaurus comes from the ancient Greek word thesauros , which means treasure or treasure trove . Unsurprisingly, the word for thesaurus in Latin is also "thesaurus" and refers to a thematically ordered collection of certain criteria in which objects are related one to another – a "storehouse of knowledge" if you will. A thesaurus is essentially a dictionary based on linguistics and information science, that compiles the entire vocabulary of a language.
In the 1950s, the thesaurus became a specialized reference book with controlled, limited vocabulary pertaining to individual words as well as their relations to other words. The basis for the vocabulary used in a thesaurus was developed under the authority of the German National Library [2] and the Library of Congress Subject Headings (LCSH) [3]. Synonyms, as well as generic terms and narrower terms, are primarily used. The relationships between the terms are standardized in accordance with DIN 1463-1 (more specifically ISO 2788) and are known as associations and references.
Current examples include the thesaurus Linguae Latinae (abbreviated ThlL or TLL) [4] for Latin, Linguae Graecae (TLG) [5] or the UNESCO Thesaurus [6].
The latter is more of a collective work in the area of education, science, culture, social sciences and humanities, information and communication sciences, political science, law, and economic sciences. All of the entries are in English, French, Spanish, and Russian. The European Thesaurus on International Relations and Area Studies [7] and the Getty Thesaurus of Geographic Names (TGN) [8] are also very useful. These are now available as open data for anyone who is interested (Figure 1).
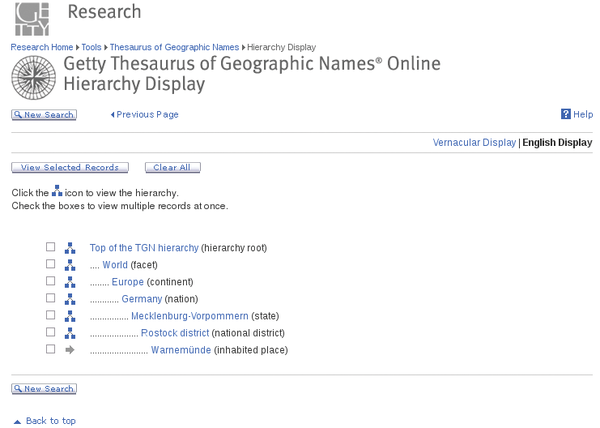 Figure 1: Detailed search results and hierarchy for the German term "Warnemünde" on TGN.
Figure 1: Detailed search results and hierarchy for the German term "Warnemünde" on TGN.
Linguistic thesauri are based on applied linguistics and use mindmaps to organize vocabulary. The main goals for this are to display the invisible connections (semantics) between words of different origins and to illustrate the similarity (relations and associations) between each word.
Additionally, thesauri serve to explore the history of language and to determine specific meanings and their history. Thesauri assist people in day-to-day life as dictionaries of synonyms. These references can help create you more elegant expressions and may also help you become more skillful in a given language.
In IT, thesauri often come bundled with word processors, as well as with search engines. They often form the basis for spellcheckers and reinforce assistance with proper grammar. KThesaurus [9] and OpenThesaurus for LibreOffice [10] are just a couple examples of the practical application of thesauri.
Projects and Tools
The Swiss website Lexikon.ch [11] offers an introduction to research in German-speaking countries. This offers a special search engine for encyclopedias, thesauri, dictionaries, quotation collections, abbreviations, and rhyming dictionaries. The site catalogs both commercial and free projects.
Woxikon [12], Leo [13], and Beolingus/Dict [14], among others, are offered solely online. Woxikon and Leo offer supplemental information for Slavic, Romance, and Scandinavian languages. Beolingus/Dict focuses on English, Spanish, and Portuguese. Leo and Beolingus/Dict were developed through the scientific endeavors of TU Munich and TU Chemnitz, and they work in cooperation with the French National Center for Textual and Lexical Resources (CNRTL) [15] in Nancy (Lothringen) as well as with OpenThesaurus [16] and WordNet [17].
Commercial thesauri as resources were traditionally presented in book form (e.g., Oxford English Dictionary, Roget's, German Standard Edition of Duden). Most publishers integrate their thesauri into their online editions and make it possible to use on a web browser or mobile app. Admittedly, these websites are more oriented toward occasional users.
The publishers provide an interface (API) for unlimited use and integration into your own application. Working with this requires that you register and acquire an API key. You will need to use this key for every query.
The Macmillan Dictionary [18], Merriam-Webster [19], and Cambridge Dictionaries Online [20] provide their results in XML Data or Javascript Object Notation (JSON) and comply with current, accepted web standards. Listing 1 shows a query on Merriam-Webster and Listing 2 displays the subsequent search result.
Listing 1
Merriam-Webster Query
http://www.dictionaryapi.com/api/v1/references/thesaurus/xml/umpire?key=API-Key
Listing 2
Merriam-Webster Result
<entry id="umpire"> <term> <hw>umpire</hw> </term> <fl>noun</fl> <sens> <mc>a person who impartially decides or resolves a dispute or controversy</mc> <vi>usually acts as <it>umpire</it> in the all-too-frequent squabbles between the two other roommates</vi> <syn>adjudicator, arbiter, arbitrator, referee, umpire</syn> <rel>jurist, justice, magistrate; intermediary, intermediate, mediator, mediatrix, moderator, negotiator; conciliator, go-between, peacemaker, reconciler, troubleshooter; decider</rel> </sens> </entry>
The competing dictionary publishers Pons and Langenscheidt take two slightly different approaches. Pons provides a connection to an in-house database as a standalone service [21]. Langenscheidt, on the other hand, focuses their offerings in the form of print books and specific apps for different mobile devices.Visual Thesaurus [22] allows users to take a look at the facets of individual words by the way of graphs. These graphs show the connections between words visually as individual nodes and edges in a web browser (Figure 2).
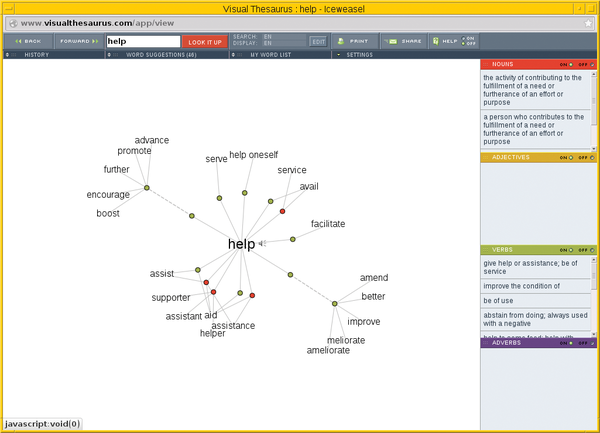 Figure 2: The Visual Thesaurus website maps out the connections between words on a tree, using the word "help" in this example.
Figure 2: The Visual Thesaurus website maps out the connections between words on a tree, using the word "help" in this example.
The image is created with Javascript and can be rotated in any direction, by clicking on the desired node. If you don't have an API key, you may make only a limited number of queries. Enough queries are generally provided to give the user an impression of the service.
Wordnik
The commercial product Wordnik [23] is a kind of enhanced dictionary for the English language that focuses particularly on the issue of mobile devices. The range of functions includes descriptions, explanations of the meanings of the word, as well as a large number of examples. Wordnik combines results from many different sources simultaneously (i.e., from Wiktionary or WordNet). See Figure 3.
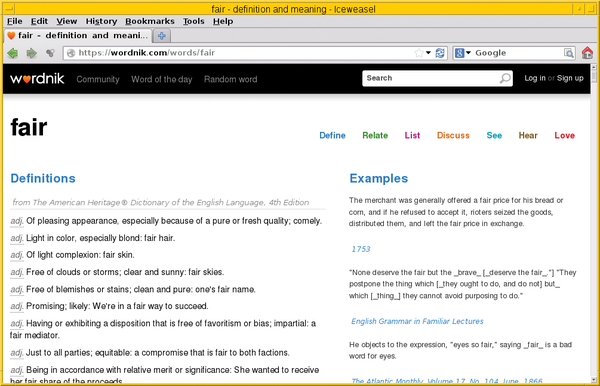 Figure 3: The commercial product Wordnik is characterized by a clear and well-structured search result.
Figure 3: The commercial product Wordnik is characterized by a clear and well-structured search result.
All modules are available under the Apache license. The source code can be found in a GitHub repository. The connection is possible via various modules and interfaces for Python, Ruby, JavaScript, Java, and PHP. The application requires registration by the manufacturer before you receive the corresponding API key.
Free Thesauri
Many thesaurus projects are available in free software. Although most are not as well known as their proprietary counterparts, they often manage to be as feature-rich. The aforementioned WordNet is the result of a research project by the same name from Princeton University. The institution has been working on an English lexicographical database for several decades.
The database groups nouns, verbs, adjectives, and adverbs at the semantic and lexical level. The project forms the basis for comparative linguistics and natural language processing, and is therefore the basis for several of the programs presented here.
In addition to a web-based interface, the current state of research for various platforms is also available (as an Ubuntu package [24], among others). This includes both a wn command-line program, as well as a graphical application called WordNet Browser.
With the query in Listing 3, you can gain insight into the synonyms for and meaning of the substantive "fair." The parameter -synsn stands for and selects synonym, whereas n does the same for substantives (English nouns). Using the command wnb , you can start the GUI program and type in the search box on the top left.
Listing 3
Synonyms for "fair"
01 $ wn fair -synsn 02 03 Synonyms/Hypernyms (Ordered by Estimated Frequency) of noun fair 04 05 4 senses of fair 06 07 Sense 1 08 carnival, fair, funfair 09 => show 10 11 Sense 2 12 fair 13 => gathering, assemblage 14 15 Sense 3 16 fair 17 => exhibition, exposition, expo 18 19 Sense 4 20 bazaar, fair 21 => sale, cut-rate sale, sales event
Below the input box, four buttons appear that display the respective available word form. To restrict the list on synonyms for nouns, click the "Noun" button and select "Synonyms, ordered by estimated frequency" from the list. The result (Figure 4) is identical to the output on the command line.
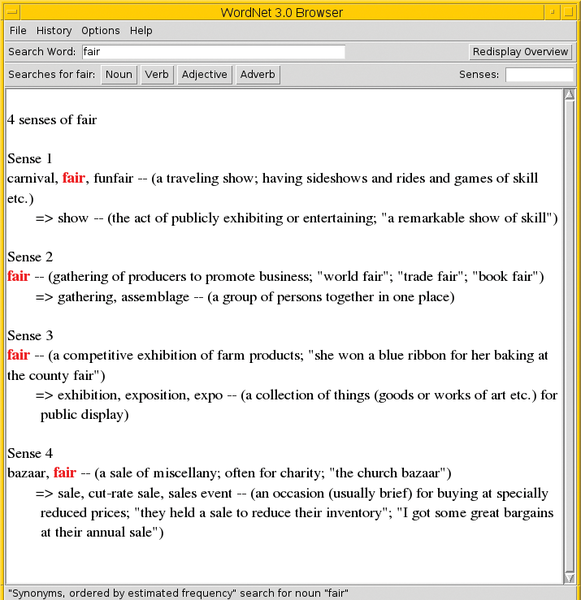 Figure 4: Query for the term "fair" in the WordNet browser.
Figure 4: Query for the term "fair" in the WordNet browser.
Several implementations exist for WordNet and are listed on the project website. To use Perl, it is best to use the WordNet-QueryData module [25], which is available as an Ubuntu package libwordnet-querydata-perl .
For Python, the Python Natural Language Toolkit (NLTK) is a good choice [26]. The latter provides a suitable parsing class for WordNet.
Kthesaurus
Kthesaurus (Figure 5) provides similar functions for Calligra-Suite (formally KOffice) as OpenThesaurus does for LibreOffice.
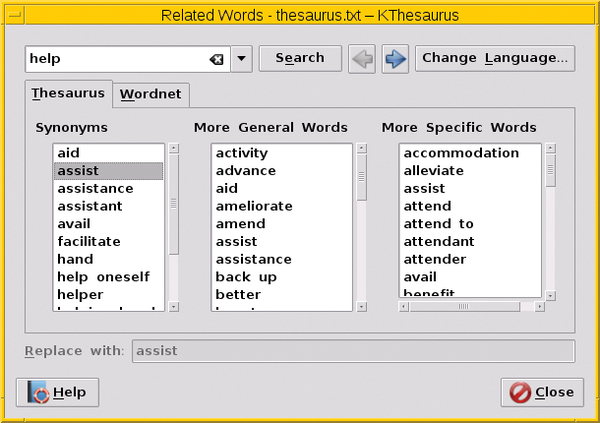 Figure 5: Kthesaurus obtains its data from the WordNet, which enables it to function only with English words.
Figure 5: Kthesaurus obtains its data from the WordNet, which enables it to function only with English words.
The lexical information gets extracted from the WordNet databank. Because of this, Kthesaurus is only available in English. To use the software, install the package for your distribution.
In the box in the top left, first enter the word you want and scroll over the Search button to search within the database. Then, under the Thesaurus tab, you will see three columns filled with synonyms (column 1), hypernyms (column 2), and hyponyms (column 3).
The Replace button replaces the word in the text with the selections (note that this is only possible if you have activated Kthesaurus from within Calligra-Office). You can change the search vocabulary by selecting one of the entries from the columns with a double click. By using tabs, you can switch between the original search and the entry from the WordNet databank.
Figure 6 displays the overview for the word "help" and is sorted according to the average frequency. Use the drop-down box to get more information in accordance with the way these are stored in the WordNet databank (i.e., by compound words, synonyms, antonyms, and everyday words).
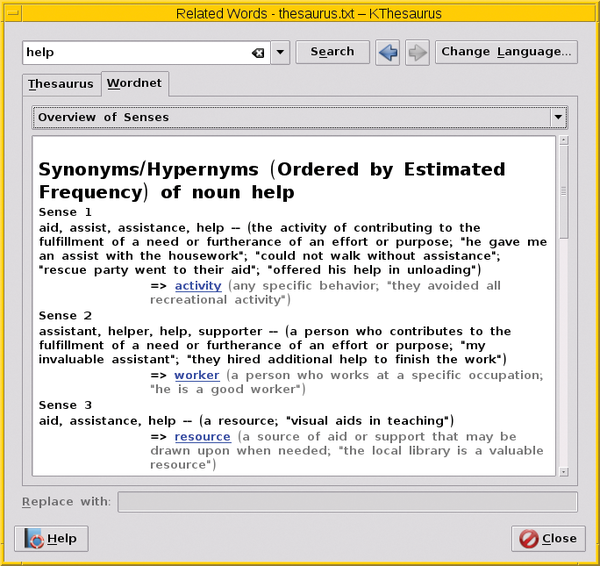 Figure 6: Search results for "help" from the WordNet database using Kthesaurus.
Figure 6: Search results for "help" from the WordNet database using Kthesaurus.
GoldenDict
GoldenDict [27] combines different sources under a unified user interface. The desktop application is based on Qt and Webkit-Framework [28]. The Ubuntu program package can be found under goldendict .
This program serves as an interface to various dictionaries and data sources including Wikipedia, Wiktionary, and WordNet in order to derive and compile the information. As a user, you can specify which program channels to evaluate in the settings. In the input box at the top left, you must first enter a search item. Then, similar items from which you can select will appear in the left column. In the middle column, you will see the search results, and in the right column you will see the sources the app used (Figure 7).
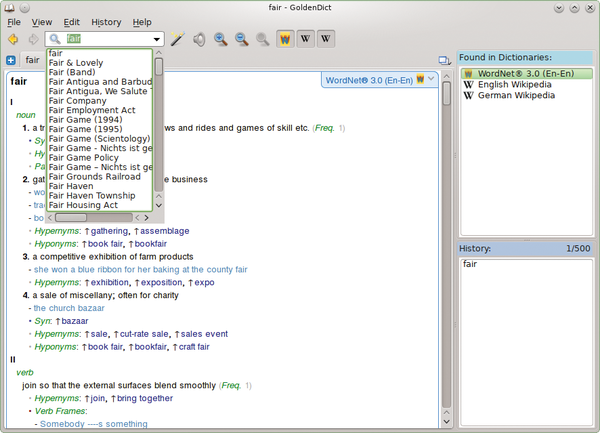 Figure 7: Goldendict combines the search results from various sources for the term "fair" in one window.
Figure 7: Goldendict combines the search results from various sources for the term "fair" in one window.
The term "fair" was used in the example query for Wikipedia in both German and English, as well as on the WordNet databank. The latter is shown as an edited search result here.
To use a thesaurus based on WordNet, you will need the goldendict-wordnet package from the package sources, which will let you connect the two projects together.
Wiktionary
Wiktionary [29] is one of the more impressive Wikipedia offshoots with its now more than 370,000 entries in more than 200 languages.
Although Wiktionary is primarily used as a dictionary, it records hyphenation rules, pronunciation, meaning, origin, synonyms, and antonyms (Figure 8). Additionally, Wiktionary is used mainly from a web browser, although there is an API to integrate it within your own projects online [30].
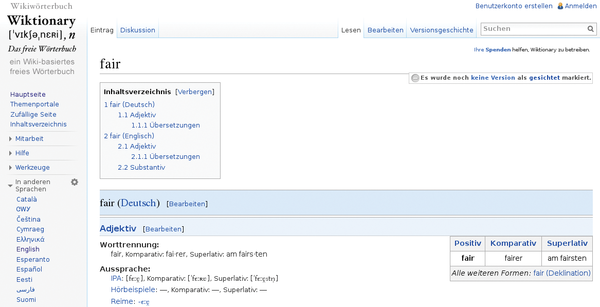 Figure 8: Search results for the term "fair" using Wiktionary.
Figure 8: Search results for the term "fair" using Wiktionary.
Conclusion
This article provides an overview of different thesauri, which are available either commercially or for free. Whether you are doing a quick search in your web browser or via the command line, there is a thesaurus for everybody out there.
Infos
- "Cluster-Based Web Searches" by Frank Hofmann, Linux Intern 01/2013, Data Becker Verlag, 2013
- Deutsche National Bibliothek – Subject Authority File: http://www.dnb.de/EN/Standardisierung/standardisierung_node.html
- Library of Congress Subject Headings: http://id.loc.gov/authorities/subjects.html
- Thesaurus Linguae Latinae: http://www.thesaurus.badw.de/english/
- Thesaurus Linguae Graecae: http://www.tlg.uci.edu
- UNESCO Thesaurus: http://databases.unesco.org/thesaurus/
- European Thesaurus on International Relations and Area Studies: http://www.fiv-iblk.de/information/information_thesaurus.htm
- Getty Thesaurus of Geographic Names: http://www.getty.edu/research/tools/vocabularies/tgn/index.html
- KThesaurus (Debian package): https://packages.debian.org/wheezy/kthesaurus
- OpenThesaurus for LibreOffice (Debian package): https://packages.debian.org/ca/source/wheezy/openthesaurus
- Lexikon.ch: http://www.lexikon.ch (in German)
- Woxikon: http://www.woxikon.com/
- Leo: http://www.leo.org/index_en.html
- Beolingus/Dict: http://dict.tu-chemnitz.de/
- French National Center for Textual and Lexical Resources: http://www.cnrtl.fr (in French)
- OpenThesaurus: http://www.openthesaurus.de (in German)
- WordNet: http://wordnet.princeton.edu/wordnet/
- Macmillan Dictionary: http://www.macmillandictionary.com/tools/aboutapi.html
- Merriam-Webster: http://www.merriam-webster.com/netdict.htm
- Cambridge Dictionaries Online: http://dictionary-api.cambridge.org/
- Pons: http://www.pons.com/specials/api
- Visual Thesaurus: http://www.visualthesaurus.com
- Wordnik: http://developer.wordnik.com
- WordNet (Ubuntu package): http://packages.ubuntu.com/trusty/wordnet
- WordNet-QueryData Perl module: http://search.cpan.org/~jrennie/WordNet-QueryData/
- Python Natural Language Toolkit (NLTK): http://www.nltk.org
- GoldenDict: http://goldendict.org
- WebKit-Framework: http://www.webkit.org
- Wiktionary: https://www.wiktionary.org/
- Wiktionary API: http://en.wiktionary.org/w/api.php