Small shell tools for text editing
Many small programs can help you with your "word tasks" in the shell. Table 1 shows an overview of which ones to use. Unless indicated otherwise, they work with single or multiple files as well as pipe operations. Some applications overlap in their functionality.
 Table 1
Table 1
To follow along with the examples shown in this article, you can grab the files a.txt , b.txt , c.txt , d.txt , and e.txt from our FTP server [1].
Showing, Piping, and
Merging
The cat and tac tools differ mainly by the output order of the content: cat puts the file in its original order, and tac reverses the order. The scope of their options is also different (see Table 2). You can also add line numbers using cat (Figure 1), including blank lines.
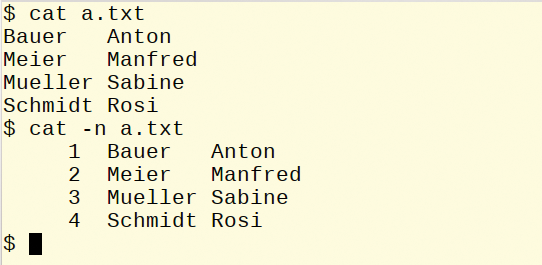 Figure 1: Using cat and tac, output of a text file as standard out.
Figure 1: Using cat and tac, output of a text file as standard out.
 Table 2
Table 2
Instead of sending output to the screen, you can send the content of a text file to another application for further processing. You can do this with both cat and tac .
In the following example, the wc command (described later) counts the lines that cat passes on to it:
cat a.txt | wc -l
For vertical or serial merging of text files (i.e., appending one file after the other), you can pass on the filenames as parameters and, optionally, a target file to copy the result into the following format:
cat [FILE1] [FILE2] ... > [TARGETFILE]
The target file isn't necessary if you want to pass the data through a pipe or to the screen.
Heads and Tails
Using head , you output the beginning of a text file, and with tail , you output the end. These programs provide slightly different options, as described in Table 3. You can use both commands for text files or pipes.
 Table 3
Table 3
In practice, you'll mainly want to read a specific number of lines at the beginning or end of the file. Use the following to output the first five lines:
head -n5 [TEXTFILE]
Or, in the shortened form, use:
head -5 [TEXTFILE]
You could also possibly use:
...| head -n5 ..... ...| head -5 ......
You can get the last five lines with:
tail -n5 [TEXTFILE] tail -5 [TEXTFILE] ...| tail -5 .......
For the tail command, there is yet another interesting option. You can show the ongoing changes to a file using -f (follow ), which is especially useful for log files. You can also set the sleep interval between readings (Figure 2). Pressing Ctrl+C ends the output.
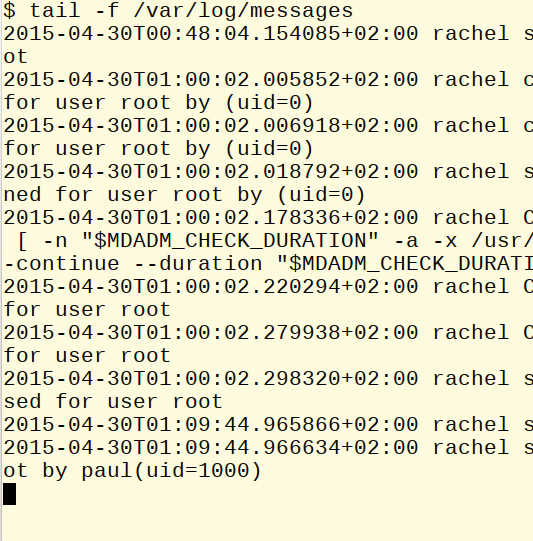 Figure 2: You can keep tabs on changes in a log file using tail -f.
Figure 2: You can keep tabs on changes in a log file using tail -f.
Both programs also let you output specific lines that aren't tagged with a line number. For example, you can do:
tail -3 [TEXTFILE] | head -1
to output just the third line from the end.
Substring Extraction
In most cases, you would use the cut program in structured text files by extracting individual data fields. The output is in the order given in the line. Alternatively, you can output by byte or character order. With data fields you need to indicate the field separator. If it's a special character (e.g., tab) you need to escape it with \ .
Table 4 describes the options. You can follow a field, byte, or character number with a minus sign (-) to indicate extracting everything from it to the end of the file. A minus sign between two values indicates a range.
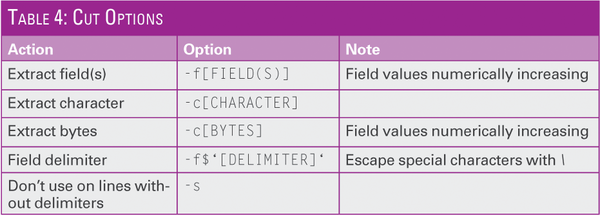 Table 4
Table 4
Figure 3 shows how cut works. In the first example, you can see how the second field is extracted from the structured line (the field delimiter is the tab character). The second example extracts characters 5 through 8 from each line. Although awk is covered elsewhere in this issue, it's worth mentioning here if only to point out how awk and cut differ. Unlike cut , you can use awk to extract columns of a structured text file in any order.
 Figure 3: Extracting data fields and characters using cut.
Figure 3: Extracting data fields and characters using cut.
This functionality could be interesting if you need to merge CSV files. You can set variables inside loops and extract the data (e.g., letter greetings based on recipients). The calls take the following form:
awk '{OFS="[FIELD_DELIMITER"; print $[FIELD], $[FIELD] ...}' [TEXTFILE]or, you can do:
... | awk '{OFS="[FIELD_DELIMITER"; print $[FIELD], $[FIELD] ...}' ...Figure 4 shows an example of how an awk call would work within a pipe. The field delimiter I have chosen is a tabulator character (which is the default delimiter awk uses anyway). The two columns of the file will be reversed.
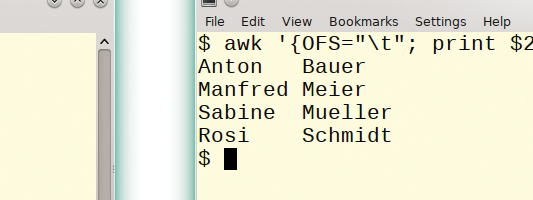 Figure 4: Extracting data fields using awk.
Figure 4: Extracting data fields using awk.
Searching with grep
With grep , you can search through text files or data streams in pipes. Numerous options are available in shell scripts or by direct calls.
Table 5 shows a selection. The grep search patterns can also be regular expressions (regex). Some of the examples may have multiple solutions! You can use special designations in search patterns for character classes (Table 6). Note the character classes in double brackets ('[[:alpha:]]' ). You can basically use all options within a pipe, as long as they don't relate to files or directories (-l and -L ).
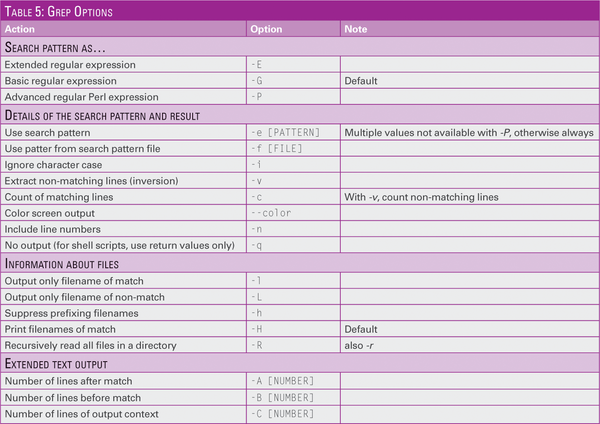 Table 5
Table 5
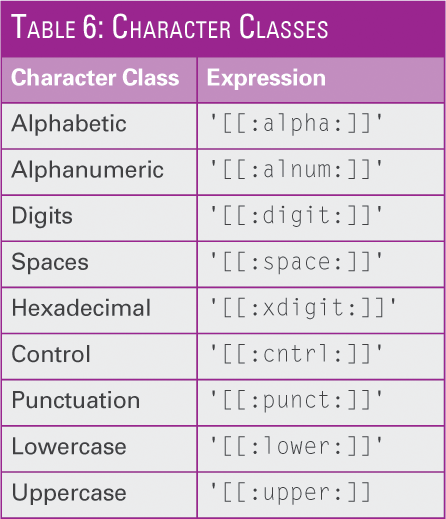 Table 6
Table 6
For shell programming, the grep return values are important: 0 means found and 1 means an error; other errors are acknowledged with exit code 2. For testing purposes and as a short experimental platform, you can use the searchwithgrep.sh script in Listing 1. You can cancel the input using Ctrl+C. Figure 5 shows the outcome for both, and Table 7 shows some additional possibilities.
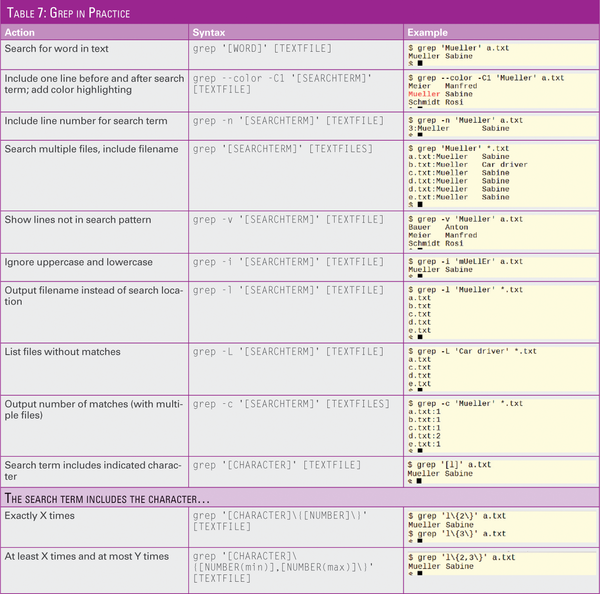 Table 7
Table 7
Listing 1
searchwithgrep.sh
01 #! /bin/sh 02 while true; 03 do 04 echo -n "Enter search term: ";read search_term 05 cat a.txt | grep -q $search_term 06 return_value=$(echo $?) 07 if [ $return_value -eq 0 ]; 08 then 09 echo "Search term found." 10 elif [ $return_value -eq 1 ]; 11 then 12 echo "No match!" 13 fi 14 done
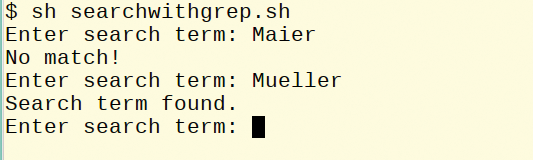 Figure 5: Output of searchwithgrep.sh.
Figure 5: Output of searchwithgrep.sh.
Less
A convenient program for scanning and searching is less . This goes for text files as well as in pipes. For example, you can do the following:
less [TEXTFILE]
or
... | less
Table 8 shows the most important options. How you eventually work with the program depends largely on the terminal characteristics, which is particularly true of navigation in text. You can quit the program using Ctrl+Q.
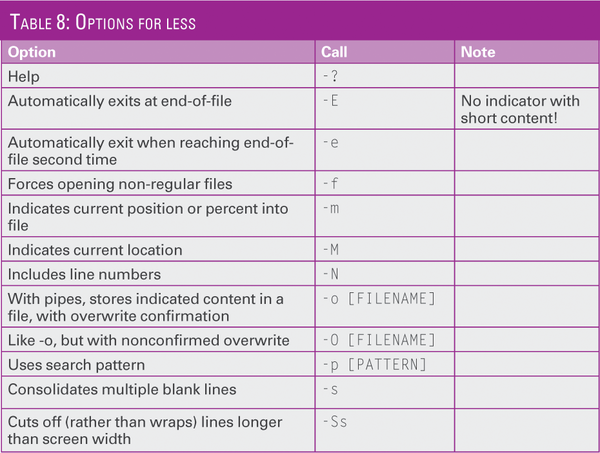 Table 8
Table 8
To navigate around the files that you browse with most distributions, you can simply use the arrow keys or use the keys described in Table 9.
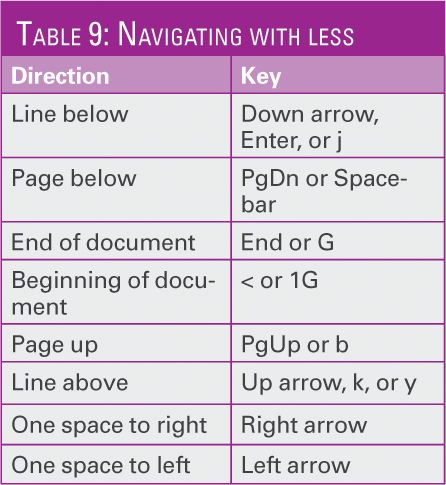 Table 9
Table 9
If you're scanning through a text file with less , you can press v to open it in an editor. If you do so while less is working on a pipe, an error message appears. Entering /[SEARCHTERM] will begin the search. The results are highlighted in reverse video on the screen.
Statistics with wc
The wc command is interesting if you need to pay particular attention to characters, words, or lines. For example, you can use wc to provide parameters to prepare for printing. The wc command can be applied directly to files or can be piped. Table 10 shows the main options.
 Table 10
Table 10
The GNU version of wc described here provides, among other things, the option to extract the number of characters in the longest line of the document. You can use this information to create an attractive print output for encscript or latex , because this is an important factor in the choice of font size or page orientation. Running the program without options gives you the line, word, or byte count. Figure 6 provides some examples.
 Figure 6: Examples of wc.
Figure 6: Examples of wc.
Numbering Lines
You can impose line numbering for (print) output independently of an editing (or other) application. The nl program works with text files and pipes. Table 11 lists the options.
 Table 11
Table 11
For example, you would do the following:
cat e.txt | nl -v 10 -i10 -ba -w 3-nrz
to number all lines in the piped data with a starting value of 10 and an increment of 10, making the numbers three characters (000 ) wide.
Sorting Files
You often might need the sort function to sort out multiple identical lines from a pipe. Of course, sort also serves for all other sorting tasks. Table 12 gives a quick overview of the sort functions. Note that it's not just about forward and backward sorting, but also about what is being sorted.
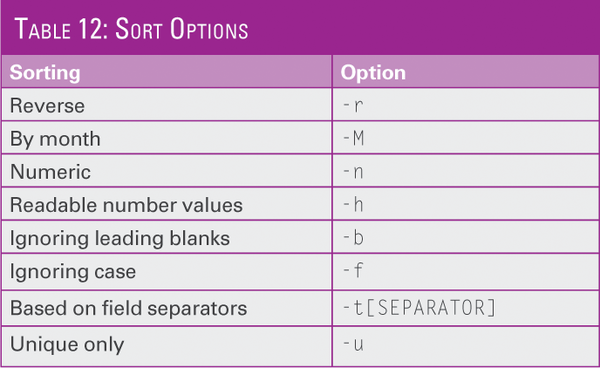 Table 12
Table 12
The following command:
cat *.txt | sort -u
outputs all items in a folder, with multiple occurrences of identical lines suppressed.
Removing Identical Lines
In overflowing log files with tons of consecutive identical messages, the uniq command helps provide clarity. However, it can also be used when searching for duplicates. To handle duplicates, the input or piped data needs to be sorted. Table 13 includes a few of the most important options.
 Table 13
Table 13
In the first example that follows, you can concatenate all the text files, sort them together, and output only the duplicate lines prefixed with their occurrence count:
cat *.txt | sort |uniq -dc
Next, you can extract only the unique lines from the data sources:
cat *.txt | sort | uniq -u
And, in this example:
cat *.txt | sort | uniq
all duplicates are removed from the pipe output and both the unique and duplicate lines are displayed.
Substituting and Deleting Characters
Using the tr command, you can substitute or delete (single) characters in a pipe. You delete using the -d option. You can also replace consecutive identical characters with just one using -s . Character classes can also be used. As with sed , you can set search and replace patterns through character ranges in the form [CHAR1-CHAR2] . The substitution is one to one, but you can have one substitution for multiple searches and vice versa.
Special characters are escaped with \ for evaluation. Most often, you would use the form feed (\f ), new line (\n ), or horizontal tab escape (\t ) sequence. The manual also includes further options.
The examples in Figure 7 show the following action:
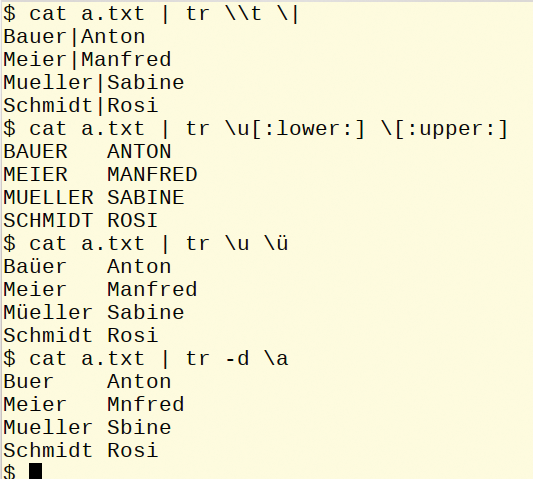 Figure 7: Different uses of the tr tool.
Figure 7: Different uses of the tr tool.
- Substitution of tabs with the | symbol.
- Replacement of all characters with uppercase.
- Replacement of all u characters with their German umlaut equivalents.
- Character deletion
You can set the search and replace entries as variables. Listing 2 shows a short shell script that uses variables instead of fixed patterns.
Listing 2
Script Using tr
01 #! /bin/sh 02 echo -n " Search: ";read search_term 03 echo -n "Replace with: ";read erbe 04 cat a.txt | tr "$search_term" "$erbe"
Octal Format
You can use od to dump a file or output of a pipe into octal or some other format. The program can help track down (not always reproducible) special characters. Without options, the output is in octal bytes.
Using the -c option, the output extracts into ASCII, with special and control characters indicated. Using -x , it shows the information in hexadecimal.
Converting Character Sets
Various character sets have existed for a while, making data exchanges difficult at times. With the recode program, you can convert the text file to a desired character set. Probably the most important option is -l , which lists all the known source and destination character sets. With -f , you can force recodings under all circumstances and the process is irreversible. The -v option provides a verbose summary of the conversion process itself.
Further options are described on the manual web page.
The smart method is to copy the file to be converted and avoid using the original. The recode -l command will get you the character set information. You can then apply the conversion to the copied file.
The syntax is as follows:
recode [OLD_CHARACTER_SET]..[NEW_CHARACTER_SET] [FILENAME]
Necessary control characters are also added, such as CR or LF. As an example, you would do the following:
cp a.txt exported.txt recode -v UTF-8..ISO-8859-15 export.txt
to convert a file from its original UTF-8 character set to ISO-8859-15.
Replacing Tabs
The expand and unexpand programs adapting tabs within texts (in files as well as pipes). Both use the -t[NUM] option that determines how many space characters to substitute for a tab (normally eight).
With unexpand , you can use the -a option to convert all spaces (not just the first one) into tab characters. Note that using tr has pretty much the same effect.
Combining Texts
You use the paste tool for this. Each text file is considered a "column" in the target file. The "montage" works as follows:
paste [FILE1] [FILE2]
You can, of course, direct the output to a new file.
The tool does not in any way evaluate what is on each line. It just pairs them up. Figure 8 shows an example.
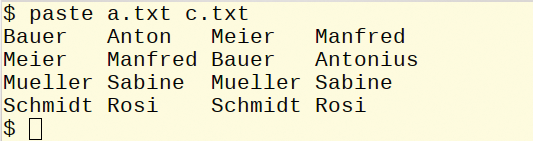 Figure 8: Text files combined as columns using paste.
Figure 8: Text files combined as columns using paste.
Joining Two Files
With the join command, you join the rows of two tables using a common key. The two tables need to be sorted first. To gain a better understanding of how this works, you can take a look at some of the sample files first. The format of the command is join [-OPTION] [FILE1] [FILE2] .
Table 14 shows the most important options. If you omit any field values, the first column of the file is used by default.
 Table 14
Table 14
Figure 9 shows how join works. In the first example, without any options, the first field is the common key. In the second example, all non-joinable lines in the first file are printed to the output. Finally, all incorrect sorting error messages are removed and the columns for joining get printed. Of course, any further possible pairings are omitted due to any sorting errors.
 Figure 9: Joining text files using join.
Figure 9: Joining text files using join.
Splitting Files
The split command is used to split large files into manageable pieces to fit on smaller media. You can store split documents in different places to make it harder for someone to assemble them for nefarious reasons. You can always reassemble the files using cat .
Table 15 lists the most important options. The size values you can give in bytes (without further additions), kilobytes (K), megabytes (M), or gigabytes (G). In most cases, you would use a filename prefix. The command has the form split [-OPTION] [FILE] [PREFIX] . You would use a dash symbol instead of the filename in a pipe.
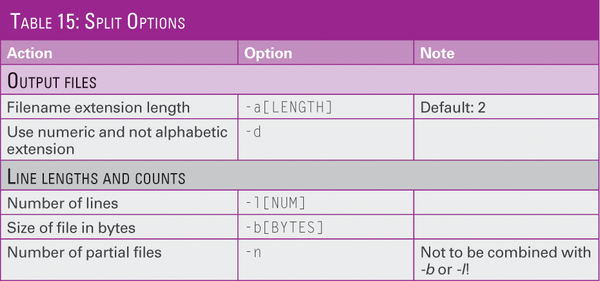 Table 15
Table 15
I'll show three examples. After each example, you can check out the result by using cat on the files that begin with Part.* in your work directory.
First, divide a file into a predetermined number of subfiles using
split -n2 a.txt "Part."
Note the dot at the end of the prefix value. You can use a pipe and specify a file size for splitting the file as follows:
cat a.txt | split -b20 - "Part."
The next example shows how to split a file line by line, which can help in structuring files for extracting addresses (roughly the same as using head and tail ). In the case of split , numeric entries are required:
split -d -l2 a.txt "Part."
In some ways, the csplit instruction is similar to cut , except that it splits a file vertically based on patterns. You should already be familiar with some of the options shown in Table 16.
 Table 16
Table 16
The pattern is expressed as /…/ . The file is split on the first occurrence of the pattern. You can also provide a number or {*} for "repeat the pattern as many times as possible" to generate the subfiles. The usual rules apply to the search patterns as far as escaping the shell special characters. If using a pipe, be sure to enter a dash instead of the filename.
To see how this works, you can copy the a.txt to h.txt and add three dashes at the beginning of each line, as shown in Listing 3. This is the separator in csplit for creating subfiles.
Listing 3
h.txt
01 --- 02 Bauer Anton 03 --- 04 Meier Manfred 05 --- 06 Mueller Sabine 07 --- 08 Schmidt Rosi
Next, create the subfiles from h.txt .
csplit h.txt -z -f "Part." /---/ {*}Check the result by using cat on the files that begin with Part.* in your work directory.
Wrapping Text
If you want to wrap long lines of text in a controlled way, you can use the very handy fold command and its options:
fold -sbw[COLUMNS] [FILE]
You can also use the fold program in a pipe, in which case you would omit the filename. The -b option indicates the bytes instead of columns, which prevents surprises involving control characters. To prevent breaking up words, you can use -s to break at spaces only. Use -w[NUM] to indicate the number of columns different from the default 80.
It's not advisable, however, to use fold as a cut substitute if you want to split lines by fields. With addresses, for example, house numbers and street names commonly end up on different lines.
Line-by-Line Comparisons
With diff you can determine content differences between files. Table 17 shows some of the options. You can also use the program to verify identical files. Some of the functions are similar to those for join . The exit code for identical documents is 0 . If the documents are different, the tool will exit with 1 .
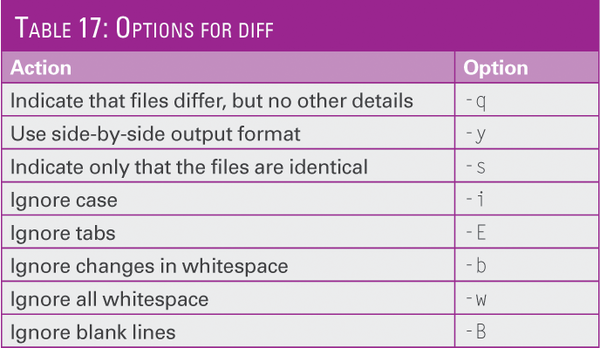 Table 17
Table 17
Compare the a.txt and c.txt files, for example. Figure 10 shows some of the possible options you can use. The first example shows the differences one at a time. The 1d0 entry and others are editor commands that I won't be covering here. The second example shows the results in columns. The third example shows the "silent" execution and exit codes.
 Figure 10: Determining file content differences using diff.
Figure 10: Determining file content differences using diff.
Conclusion
Many shell helpers can supplement or replace sed, and they can help you automate many of the text-processing tasks you need to perform.
Infos
- Files used in this article: ftp://ftp.linux-magazine.com/pub/listings/ubuntu-user.com/25/TextTools/