
Minimizing load time for web pages
|
Automatic
Documents composed in a markup language such as XML, LaTeX, WML, Markdown, or AsciiDoc provide the starting point for a web page. The HTML code created from these languages should be checked for accuracy after export. This step is usually done as part of optimization when trimming and simplifying the HTML output [4] and the CSS files [5].
A variety of tools and formats are available for exporting HTML, including Pandoc [6] and AsciiDoc [7], which use a formulation similar to wikis, DocBook [8], as an intermediate step, and also directly via Docbook2html.
If your documents are based on LaTeX, then you are probably already familiar with the classic LaTeX2HTML [9]. Because this language has not been developed since 2001, it makes sense to take a look at its successors TeX to HTML translator (TtH) [10], HyperLaTeX [11], PlasTeX [12], and tex4ht [13].
If you are using XML, then Saxon [14] and Htc-py [15] are helpful. An XHTML document is by definition also an XML document. If correctly exported, there are no problems for either an XML parser or most browsers. However, Internet Explorer has trouble handling XHTML documents, so it would be better to use HTML5. If you need XHTML5 because of SVG or MathML, for example, then it's best to develop polyglot documents [16].
Validating
Even though documents are generated automatically, this does not ensure that documents created during each export will comply with all of the conventions of the HTML standard.
You should always monitor the output and include HTML, CSS, and JavaScript. The result will be that you reduce errors in the display for which HTML and CSS are responsible, and in the execution when JavaScript, Ajax, jQuery, and JSON come into play.
Furthermore, a user's web browser will have an easier time correctly interpreting and displaying data it receives. As a side benefit, the network load gets reduced because fewer requests and data packets need to be sent back and forth between the web server and the browser.
The W3C Markup Validation Service [17] is the reference for validating HTML code. The service provides a reliable report for entire websites or just individual HTML files. Files get uploaded via a form, and it's easy to figure out from the report where cleanup and improvement are needed (Figure 2).
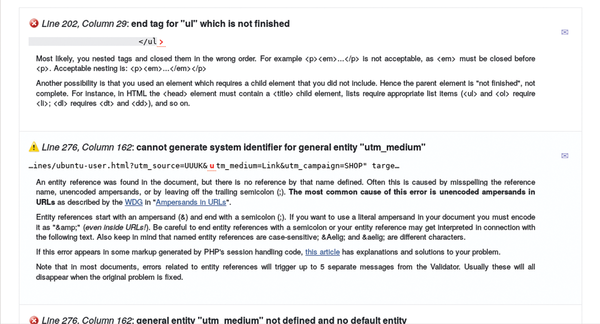 Figure 2: These are results for the validation of an existing web page from the W3C Markup Validation Service.
Figure 2: These are results for the validation of an existing web page from the W3C Markup Validation Service.
The XML Schema validator [18], which is included in the service, is fastidious but it specializes in the XHTML dialect. The Firefox plugin validator [19] and HTML validator [20] can also provide helpful assistance. They display the results of the test as a separate window. These results are based on a method established by the W3C in combination with the tools Tidy [21], Tidy for HTML5 [22] and OpenSP [23].
Check accuracy for JavaScript code is more difficult. In practice, JSLint [24] and JSHint [25] have proven helpful. Both tools can be used via a text field that is provided on the web page for each project.
After entering the JavaScript code into the field, you will immediately get an evaluation of the complexity of the program code and also a list of the errors that have been discovered. Offline tests include Acorn.js [26] and ESLint [27] in addition to JSHint.
You can use the npm package manager from Node.js for installing both of these command-line tools. In this way, you keep installation of these components separate from the package management of the distributions.
Buy this article as PDF
Pages: 5
(incl. VAT)
Buy Ubuntu User
US / Canada
UK / Australia
Related content
-
JavaScript, jQuery, and DOM model interaction

The JavaScript language has developed into an important programming language. We explain the basics and provide examples for accessing an open HTML page through the DOM interface.
-
Practical online helpers for CMS beginners

Whether it be themes and templates, JavaScript or regex, responsive design or typography, resourceful web designers make work easier for themselves with the many freely available tools on the web.
-
Overview: CMS systems without databases

When you think of CMS and blogs, names such as WordPress, Typo3, and Joomla come up. But often, much leaner solutions will suffice.
-
The very fast QupZilla web browser put to the test

QupZilla is a new Linux web browser that enters in an already crowded arena. But, QupZilla holds its own when it comes to speed and ergonomics.
-
Testing the Vivaldi web browser

Opera changed course with version 15, giving up its status as independent software and dropping many of its features. Vivaldi seeks to offer a new home to fans of the old Opera.