
Scanning and editing text with OCR
|
Unleashing the Tesseract
No clear favorites stand out among the OCR programs. Tesseract is an effective tool for everyday use. My tests used some sample text (Figure 5) that showed the strengths and weaknesses of the program. The scanned file was in TIFF format with a resolution of 600dpi. Scans of magazine articles, manuals, and book pages returned fairly indistinguishable results. Thus, a good strategy is to use both OCR programs for the shell script.
 Figure 5: Some sample text exposes the strengths and weaknesses of Tesseract.
Figure 5: Some sample text exposes the strengths and weaknesses of Tesseract.
Development of Tesseract began back in 1985. The software outputs plaintext files. The package includes utilities with which you can introduce new fonts (cntraining , mftraining ). The Tesseract OCR run appears in line 17 of Listing 1.
Tesseract currently handles the following languages: Dutch (nld ), English (eng ), French (fra ), German (deu and deu-f ), Italian (ita ), Portuguese (por ), Spanish (spa ), and Vietnamese (vie ). The scan expects images in TIFF format. Figure 6 shows a run. Tesseract recognizes special characters very well.
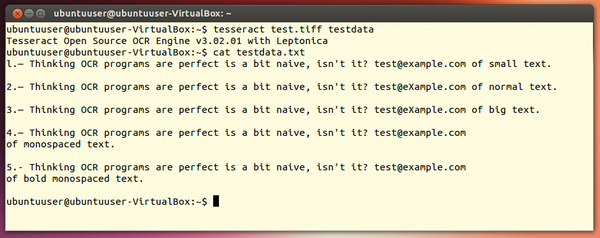 Figure 6: Tesseract evaluates special characters and numbers in many cases.
Figure 6: Tesseract evaluates special characters and numbers in many cases.
Helpers
The powerful Convert program from the ImageMagick package helps create PDF files from TIFF files. It not only provides the ability to process other formats, but it also modifies other image file properties through shell commands. The command on line 31 of Listing 1 is enough to create a PDF file.
You can use PDFtk [2] (install with sudo apt-get install pdftk ) to combine PDF files. Line 32 shows how you apply the software. Other features of the program are disassembling, rotating, encryption/decryption, and modifying PDF files.
Generating a PDF file from a text file involves several steps. Most distributions use UTF-8 as the character set in the shell. Because many conversion tools are based on the ISO-8859 character sets, the first step is to use Recode [3] to convert the text data (line 37). The program also converts ancient character sets from the 1970s.
With Enscript [4] or A2ps [5], both of which are available in the Ubuntu repositories, you can create a PS file as an intermediary step. These programs differ mainly in their output forms, and they currently work only with the ISO character sets. You can see the call to A2ps on line 38. The call to Enscript would be similar. In the last step, the script creates a PDF file from a PS file via Ps2pdf14 from the Ghostscript [6] package (line 39).
In the last step, the script assembles the scanned documents and the extracted text. This creates a document that provides the content and the opportunity to search through it with Linux tools.
« Previous 1 2 3 Next »
Buy this article as PDF
Pages: 4
(incl. VAT)
Buy Ubuntu User
US / Canada
UK / Australia
Related content
-
Paperwork in the battle against paper stacks

Paperwork is a new attempt to create the paperless office using free software components. This article describes just how far it's come.
-
Tracking down weak points in your intranet

Finding weak points and problematic configurations in an intranet typically takes a lot of time and effort. Thanks to careful integration into Kali Linux, the OpenVAS and Nmap tools can be genuinely helpful.
-
Q&A Ubuntu contributor Mike Basinger