
Create searchable PDFs and optimize their use
|
Click Through
If you would like to have more control over text recognition, then you will find that the command-line tools discussed thus far a bit lacking. This is where OCRFeeder [5] comes into play.
Most distributions have OCRFeeder in their package sources, and you can install it on Ubuntu with:
sudo apt install ocrfeeder
OCRFeeder analyzes layout and uses various OCR engines for text recognition. The supported engines include Cuneiform, GOCR, Ocrad, and Tesseract. You can select the program's OCR tool under Tools | OCR Engines .
When you fire it up, OCRFeeder will offer you the choice of scanning a new document or opening a selected document as a graphic or PDF. In order to correct scanning errors and straighten text, OCRFeeder also relies on Unpaper. You can call these Unpaper functions with Tools | Unpaper , as well as Tools | Image Deskewer .
Start the text recognition by clicking on Document | Recognize Document . Once this action is completed, the recognized text will appear in an editor window. There you can make corrections and even format the text (Figure 2). The results can be saved as a searchable PDF file. In addition to blank text files and HTML, the export function also supports output as ODT in order to continue work with the document in LibreOffice. The free office suite then opens the export as RTF, DOC, or DOCX.
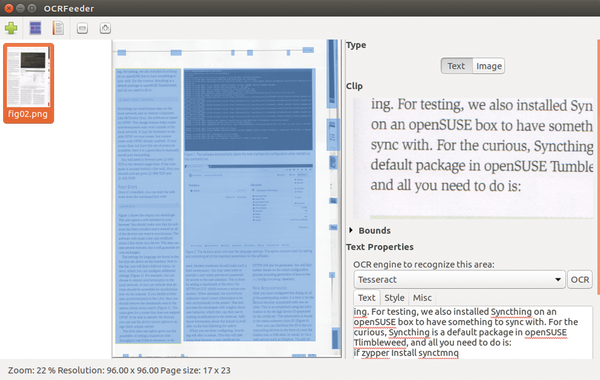 Figure 2: OCRFeeder also handles complicated layouts without any problems as shown here with an Ubuntu User article.
Figure 2: OCRFeeder also handles complicated layouts without any problems as shown here with an Ubuntu User article.
Metadata
Similarly to Exif data found in photos, PDF documents also contain optional metadata, such as title, author, document type, keywords, creation and modification dates, as well as the program used to create the PDF file. The information can be displayed with many PDF document viewers (Figure 3). The PDF toolkit [6] is available when you want to change or delete the metadata. In Ubuntu, you can install this with:
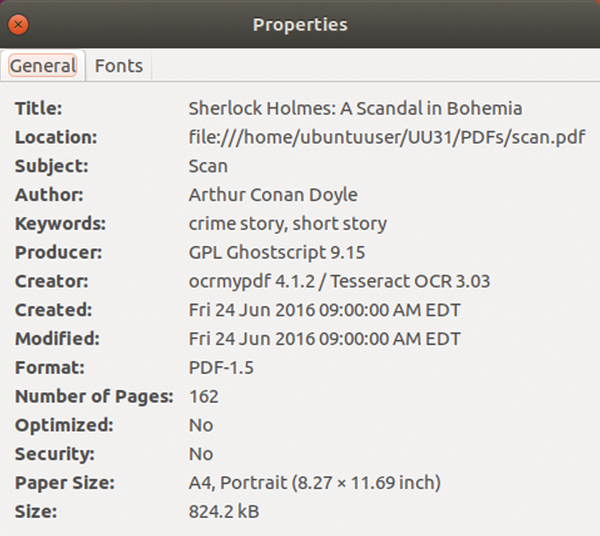 Figure 3: PDF files frequently contain additional metadata. Image viewers, such as Evince shown here, display these in the properties.
Figure 3: PDF files frequently contain additional metadata. Image viewers, such as Evince shown here, display these in the properties.
apt install pdftk
You can read out the metadata for the document scan.pdf with the commands from Listing 5 (first line), or alternatively you can write them back (second line). The metadaten.txt file serves as the buffer. Listing 6 shows how this kind of text looks. The data in lines 1 through 24 contain author, title, subject, keywords, date of creation, dates of modifications, the software program with which the original document was created prior to PDF conversion, as well as the program used to create the PDF file.
Listing 5
Reading and writing metadata
$ pdftk scan.pdf dump_data output metadata.txt $ pdftk scan.pdf update_info metadata.txt output scan_updated.pdf
Listing 6
Metadata
01 InfoBegin 02 InfoKey: Author 03 InfoValue: Arthur Conan Doyle 04 InfoBegin 05 InfoKey: Title 06 InfoValue: Sherlock Holmes: A Scandal in Bohemia 07 InfoBegin 08 InfoKey: Subject 09 InfoValue: Scan 10 InfoBegin 11 InfoKey: Keywords 12 InfoValue: crime story, short story 13 InfoBegin 14 InfoKey: CreationDate 15 InfoValue: D:20160624090000+02'00' 16 InfoBegin 17 InfoKey: ModDate 18 InfoValue: D:20160624090000+02'00' 19 InfoBegin 20 InfoKey: Creator 21 InfoValue: ocrmypdf 4.1.2 / Tesseract OCR 3.03 22 InfoBegin 23 InfoKey: Producer 24 InfoValue: GPL Ghostscript 9.15 25 PdfID0: 4b6f80885c8cd32aa1ecfd450d73905b 26 PdfID1: 4b6f80885c8cd32aa1ecfd450d73905b 27 NumberOfPages: 162
This information is arranged in blocks of three. At the beginning of a metadata block (line 1), you will see the type of information (line 2: author) and then the actual value (line 3: the author's name). Lines 25 and 26 contain two hash totals that identify the file. The first (line 25) cannot be changed, and it corresponds to the second (line 26) when you create the document. The second hash total is always new each time you modify the document. The number of pages is found in line 27.
You can use your text editor of choice to edit the data in the metadata.txt file. If you want to delete individual pieces of metadata, remove the corresponding value from InfoValue so that the only thing remaining is an empty field. Next, you should save the change to the text file and use the second command from Listing 5 to add the modified metadata to the scan.pdf file. Then you should save the new PDF file under the name scan_updated.pdf .
If you find yourself doing this kind of work frequently, then you can automate the steps with a simple shell script. To do this, save the content from Listing 7 to a text file like metadata.sh . Then make it executable with the command chmod +x metadata.sh or set the execute bit with the file properties in a file manager. Then move the file to the ~/bin directory. Ordinarily this directory is included in your PATH variable, so the shell automatically finds the command.
Listing 7
metadata.sh
01 #!/bin/bash 02 pdftk $1 dump_data output $1.txt 03 xdg-open $1.txt 04 pdftk $1 update_info $1.txt output $1.updated.pdf 05 rm $1 06 rm $1.txt 07 mv $1.updated.pdf $1
You call the program with:
metadata.sh scan.pdf
The script first reads the metadata from the relevant PDF file and saves it to the text file scan.pdf.txt (line 2). The script then opens the file automatically in the text editor (line 3). xdg-open will automatically select the editor that has been defined for the desktop environment.
As soon as you close the editor, the editing process continues. The script transfers the modified metadata to the new PDF file (line 4) and then cleans up a little bit. The old PDF file and the text file with the metadata get deleted (lines 5 and 6). The new PDF file contains the same name as the old one (line 7). When all is said and done, you get a PDF document with the same name as the beginning file, but it contains modified metadata.
« Previous 1 2 3 4 Next »
Buy this article as PDF
Pages: 8
(incl. VAT)
Buy Ubuntu User
US / Canada
UK / Australia
Related content
-
Scanning and editing text with OCR

With a small script, you can convert large amounts of scanned text into PDF files that you can then browse with typical Linux tools – all thanks to OCR.
-
Paperwork in the battle against paper stacks

Paperwork is a new attempt to create the paperless office using free software components. This article describes just how far it's come.
-
Reconstructing files with Magic Rescue

Faulty unmounts can quickly lead to disaster with SD cards and USB sticks. Magic Rescue can get your data back.
-
Creating and editing e-books with Sigil

If you want not only to enjoy e-books in EPUB format but also to create them, take a look at the easy-to-use and versatile editor from Sigil.